
Companies process millions of documents daily, from healthcare records to customer communications, all rich with personal data. The challenge? Accurately identifying and protecting sensitive information while tapping its potential for business intelligence and innovation.
Large Language Models are redefining organizational capabilities in data analysis, insight generation, and process automation. However, the widespread AI adoption has increased concerns about safeguarding Personally Identifiable Information (PII) and Sensitive Personal Information under GDPR, CCPA, and HIPAA.
As privacy regulations continue to evolve globally, traditional keyword-based classification systems increasingly fall short. These legacy approaches struggle with semantic understanding, producing false positives and missing critical data patterns that human-like AI can readily identify. Organizations need adaptive frameworks that harness LLMs’ contextual intelligence for superior privacy compliance while implementing robust governance mechanisms.
The Privacy Challenge in AI Systems
Traditional privacy protection methods have struggled to keep pace with modern AI applications. Keyword-based filtering and regex patterns lack the semantic understanding necessary to identify sensitive information in context. These rule-based systems generate high rates of false positives and negatives, missing nuanced privacy risks while flagging benign content. When organizations process millions of documents, emails, or transaction records, these inaccuracies compound into significant compliance gaps.
The stakes are particularly high given the evolving regulatory landscape. GDPR’s right to rectification and right to erasure requirements, CCPA’s consumer opt-out provisions, and HIPAA’s stringent healthcare data protections create a complex web of obligations. Organizations need systems that can automatically classify data according to multiple regulatory frameworks while adapting to jurisdictional differences in real-time.
Classification: The Foundation of Privacy Compliance
Data governance regulations mandate classification of data prior to implementing protections. GDPR separates general personal data like names and email addresses from special categories such as biometrics and health data that require stronger protective frameworks. When misclassification occurs, compliance breaks down, leaving organizations exposed to penalties. GDPR fines can reach 4% of annual revenue, while CCPA violations carry up to $7,500 per record. Traditional tools depending on keywords or regex patterns lack semantic understanding, missing context-dependent sensitive information or flagging innocent data. Employing semantic understanding rather than rigid rules minimizes false positives and negatives, strengthening compliance trust and regulatory assurance.
LLMs: Path to Context-Aware Classification
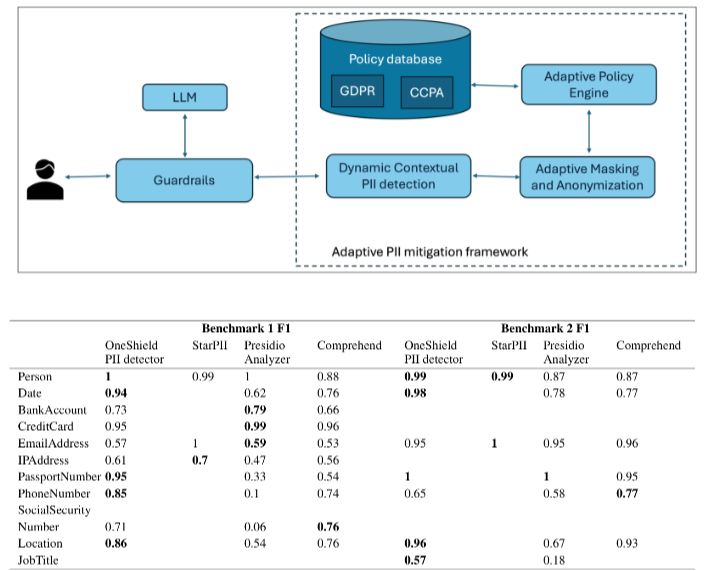
LLMs are redefining privacy practices through context-aware classification that understands data meaning rather than matching patterns. Academic research shows LLMs can automatically categorize policy clauses into legal categories such as data retention, third-party sharing, or user rights, improving analysis of lengthy, poorly structured privacy policies. IBM’s Adaptive PII Mitigation framework demonstrates how LLMs embed adaptive policies that evolve contextually across jurisdictions. GDPR mandates complete anonymization of passport numbers, whereas CCPA allows pseudonymization except when individuals opt out. Empirical benchmarks highlight these advantages, IBM’s framework achieved an F1 score of 0.95 in passport detection, exceeding Presidio (0.33) and Amazon Comprehend (0.54). These findings underscore LLMs’ potential for scalable solutions that decrease classification errors while enhancing trust.
Regulation and Adaptation
Despite progress, LLMs face hurdles achieving legal compliance across regulatory landscapes. GDPR mandates rights like Right to Rectification and Right to Erasure, challenging when data integrates into model training. CCPA emphasizes opt-out rights while Canada’s PIPEDA enforces meaningful consent, creating complex overlapping obligations. Technical solutions include machine unlearning, differential privacy, and federated learning, but require trade-offs in cost-efficiency and scalability. Adaptive frameworks offer a path forward, combining real-time policy engines with precision classification. When coupled with human-in-the-loop governance, this hybrid approach aligns with regulatory transformations while remaining user-friendly.
Practical LLM Applications
As organizations adopt LLMs, real-world use cases are emerging that showcase how regulatory compliance and data utility can coexist. These examples highlight tailored approaches across sectors, from finance to healthcare.
Healthcare
Healthcare organizations face the challenge of achieving GDPR and HIPAA compliance without compromising analytic value for predictive modeling. Electronic health records contain rich clinical information essential for medical research and AI-driven diagnostics, yet they’re filled with protected health information that must be carefully anonymized. Traditional anonymization methods often over-redact data, removing context that’s crucial for meaningful analysis.
Oracle Health’s RedactOR system demonstrates how LLMs can transform healthcare data privacy. This multi-modal framework, deployed in clinical AI systems for over 12 months, handles both text and audio redaction while achieving F1 scores of 0.9646 on standard benchmarks. The system uses one-way policies ensuring only de-identified data reaches research environments, enabling healthcare organizations to maintain HIPAA and GDPR compliance while preserving analytical value for predictive modeling and research applications.
Finance
Financial institutions must apply contextual classification to transaction logs under GDPR requirements while maintaining the data’s utility for fraud detection purposes. Transaction data contains patterns essential for identifying suspicious activities, but it’s also rich with personal information that requires careful handling. The challenge lies in creating systems that can understand the semantic context of financial transactions to identify genuine fraud risks without exposing customer privacy.
Hong Kong Monetary Authority’s deployment of SARA, an in-house LLM, exemplifies how financial regulators are leveraging AI for privacy-compliant risk monitoring. SARA analyzes 11,600 bank earnings-call transcripts from 2019-2024, extracting and classifying risk topics while implementing controls against look-ahead bias and reducing reliance on raw LLM outputs. This approach provides supervisory oversight with built-in explainability and integrity controls, demonstrating how financial institutions can use LLMs for sophisticated analysis while maintaining transparency and regulatory compliance.
Policy Communication
Organizations need to apply LLMs to analyze and simplify extensive privacy policies, making them clearer and improving user understanding. Modern privacy policies have become increasingly complex documents that most users cannot realistically comprehend, creating transparency gaps that undermine the principles of informed consent. LLMs offer the potential to bridge this communication divide while maintaining legal accuracy.
The LLM-PP2025 dataset analysis, covering 4,800+ domains, revealed that privacy policies have become longer and harder to read, with median reading levels requiring college-level education. LLM-powered simplification systems help organizations communicate privacy practices more effectively while maintaining legal accuracy.
However, implementation requires careful oversight. Research has identified “interpretation gaps” in LLM-generated policy summaries, including accuracy issues and potential false compliance assurances. Organizations implementing these systems maintain rigorous prompt design, auditability processes, and legal review workflows to ensure output quality.
Overcoming Implementation Challenges
Successfully implementing LLM-powered privacy solutions requires addressing several key challenges. Organizations must ensure accurate classification across different jurisdictions, as GDPR’s complete anonymization requirements differ significantly from CCPA’s pseudonymization allowances. Hybrid approaches combining LLM intelligence with human-in-the-loop governance have proven most effective.
Technical solutions like differential privacy, federated learning, and machine unlearning are being integrated with LLM systems to address specific privacy requirements. IBM’s Adaptive PII Mitigation Framework demonstrates how policy engines can evolve contextually to track regulatory changes, with their system recording F1 scores of 0.95 in passport detection, significantly exceeding traditional approaches.
The Future of Privacy-Preserving AI
LLMs are fundamentally reshaping data privacy practices by enabling context-aware, semantically intelligent protection systems that scale with organizational needs. These real-world applications demonstrate that organizations can maintain analytical capabilities while exceeding traditional privacy protection standards. Healthcare systems are processing sensitive patient data more securely, financial institutions are detecting fraud more effectively, and policy communication has become more transparent.
The collaboration of LLM capabilities with privacy-by-design principles creates competitive advantages for organizations that embrace these technologies early. As regulatory requirements continue evolving and data volumes grow exponentially, the organizations building robust, LLM-powered privacy frameworks today will be positioned to maintain user trust while driving innovation in their respective industries.





