Is the way to AGI through larger and larger models? What if scaling laws are not enough to get us to AGI? This question challenges the foundational assumption driving today’s AI revolution. LLMs like GPT-4, Gemini, and Claude have demonstrated remarkable S-curve growth, evolving from simple text generation to complex reasoning, coding, and multimodal understanding. The governing principle seemed simple: More high-quality data + More compute + Better algorithms = More capability. But how long can this formula hold true?
The power laws of generative AI, establishing that model size depends on input data size and compute budget, appeared to provide a reliable roadmap. Kaplan et al.’s scaling laws were effective, until everything changed. DeepMind’s Chinchilla model, four times smaller than the contemporary state-of-the-art Gopher yet achieving similar performance, shattered this approach. This “Chinchilla inflection point” exposed the limitations of pure scaling approaches.
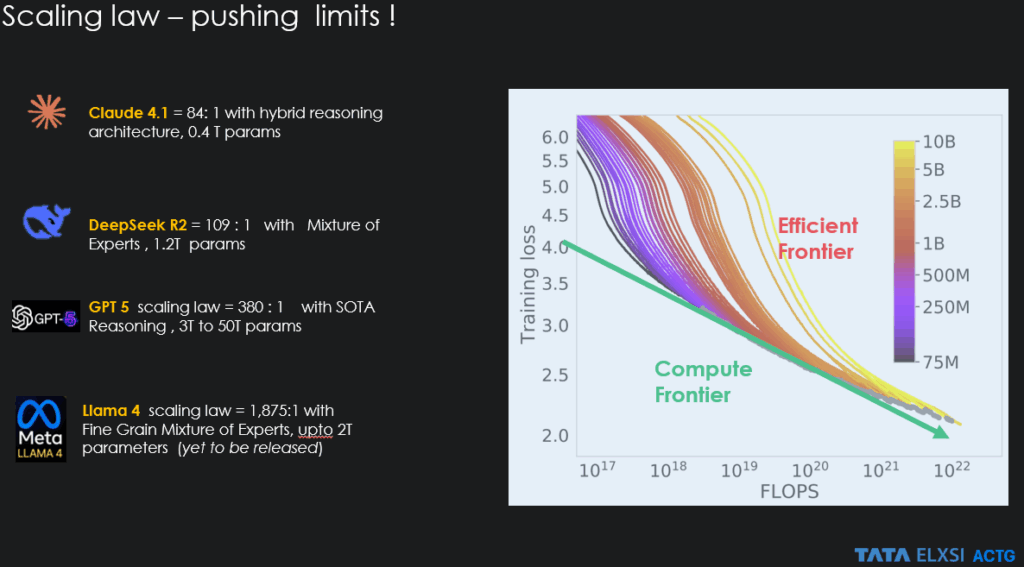
The scaling law methodology now faces challenges: constrained compute budgets, increasingly scarce high-quality data, sustainability concerns around energy-intensive GPUs, and geopolitical tensions affecting hardware access. These constraints have forced the field to innovate beyond traditional scaling. What began with Chinchilla’s modest 5:1 token-to-parameter balance has been radically transformed by breakthroughs in post-training scaling and inference. Modern architectures like Llama 4 and GPT-5 now operate at ratios of 1000:1, compressing vastly more knowledge into each parameter in a complex high dimensional space.
While scaling laws haven’t reached their theoretical limits, the path forward demands more than incremental improvements. True AGI may require revolutionary architectures beyond backpropagation-based, which transformer-based systems are capable of real-time learning, environmental adaptation, and embodied intelligence that current approaches cannot deliver.

Smarter models upends Scaling Law, a new era of smart models
The traditional method of scaling up models has diminishing returns, leading to a focus on making them more intelligent, efficient, and smarter. While scaling laws suggested predictable performance improvements with larger models, evidence now shows this relationship plateauing. Modern AI development prioritizes architectural innovations like Mixture-of-Experts (MoE), synthetic data generation, and multimodal integration over brute-force parameter expansion. Companies are achieving superior performance through “smarter” designs that optimize efficiency rather than raw size, focusing on better data curation, hybrid techniques, and specialized architectures that enhance reasoning without requiring exponentially more resources. Post-training and inference scaling, which is also called TTC or test time compute significantly raises the bar.
OpenAI o1 (and successors like QwQ, Deepseek-R1 demonstrate test-time scaling, where computational power is dynamically allocated during inference to enhance complex reasoning abilities. This became an instant hit when developers realised the power of this method.
Post-Training and Inference Scaling
Post-training techniques like reinforcement learning from human feedback (RLHF) and inference-time scaling through chain-of-thought prompting represent sophisticated methods to enhance existing models without complete retraining. These approaches make LLMs “smarter” by improving accuracy and reasoning capabilities, but they remain fundamentally limited by the underlying transformer architecture. While these methods can dramatically improve performance on specific tasks, they cannot replace the inherent weaknesses like poor reasoning or hallucinations. The core issue remains: these are optimization techniques for pattern-matching systems that struggle with true understanding, long-term planning, and the flexible reasoning required for AGI.
OpenAI’s o1 model exemplifies inference-time scaling, achieving a 64% problem-solving rate in agentic coding evaluations through reinforcement learning that teaches productive thinking patterns during inference, yet it still operates within transformer-based limitations.
Current neural networks rely on backpropagation, which excels at parallel processing but faces fundamental limits in efficiency, generalization, and causal reasoning. AGI demands versatile, self-improving intelligence that current backprop-based architectures cannot deliver due to energy inefficiency and inability to achieve human-like understanding. Research consensus indicates that 76% of experts believe new architectures are needed for AGI, as backpropagation struggles with complex reasoning, long-horizon tasks, and ethical alignment. Revolutionary approaches like brain-inspired designs, more advanced neuro-symbolic systems, and evolutionary architectures that bypass gradient-based learning are essential. These novel frameworks must integrate symbolic reasoning with neural networks, enable continuous learning, and incorporate safety mechanisms from the ground up.
Meta’s V-JEPA 2 represents this architectural evolution, using a non-generative self-supervised approach that learns from video by predicting masked segments rather than traditional autoregressive modeling, demonstrating how novel architectures can learn world models more efficiently for embodied AI applications.
The Path Forward
While scaling laws haven’t reached their absolute ceiling, the future demands more than simply building larger models. Architectural innovations like Mixture-of-Experts are enabling orders of magnitude larger models to be trained and deployed more efficiently, suggesting we’re entering a new phase of intelligent scaling rather than brute-force expansion.
The most promising developments lie in the transition from language processors to comprehensive world models. Multimodality represents a fundamental shift, integrating vision, audio, and sensor data to move models beyond text processing toward genuine world understanding. This evolution becomes even more compelling when combined with embodiment through robotics, where LLMs connected to physical systems can learn from real-world interactions, potentially solving the critical “grounding” problem that has long limited AI systems.
Perhaps most intriguingly, we’re witnessing an “intelligence snowball” effect where AI systems increasingly design better AI hardware and write superior AI software. This recursive self-improvement loop could dramatically accelerate progress, while novel architectures like Forward-Forward (FF), Joint Embedding Predictive Architecture (JEPA), and Equilibrium Propagation (EP) hold transformative potential that extends far beyond current backpropagation-based limitations.
Scaling laws showed us the path to intelligence, but the journey to AGI/ASI may require questioning the very foundations of how machines learn, adapt, and embodied intelligence. As models evolve from language processors to world models, and from backpropagation to new paradigms like JEPA and FF, we may be witnessing the early stages of an intelligence revolution.





